AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
- 1The University of Hong Kong,
- 2UC Berkeley,
- 3Tianjin University,
- 4Shanghai AI Laboratory
ICML 2023 Oral
-
 Paper
Paper
-
 Code
Code
-
 Oral Talk
Oral Talk
-
 Poster
Poster
Abstract
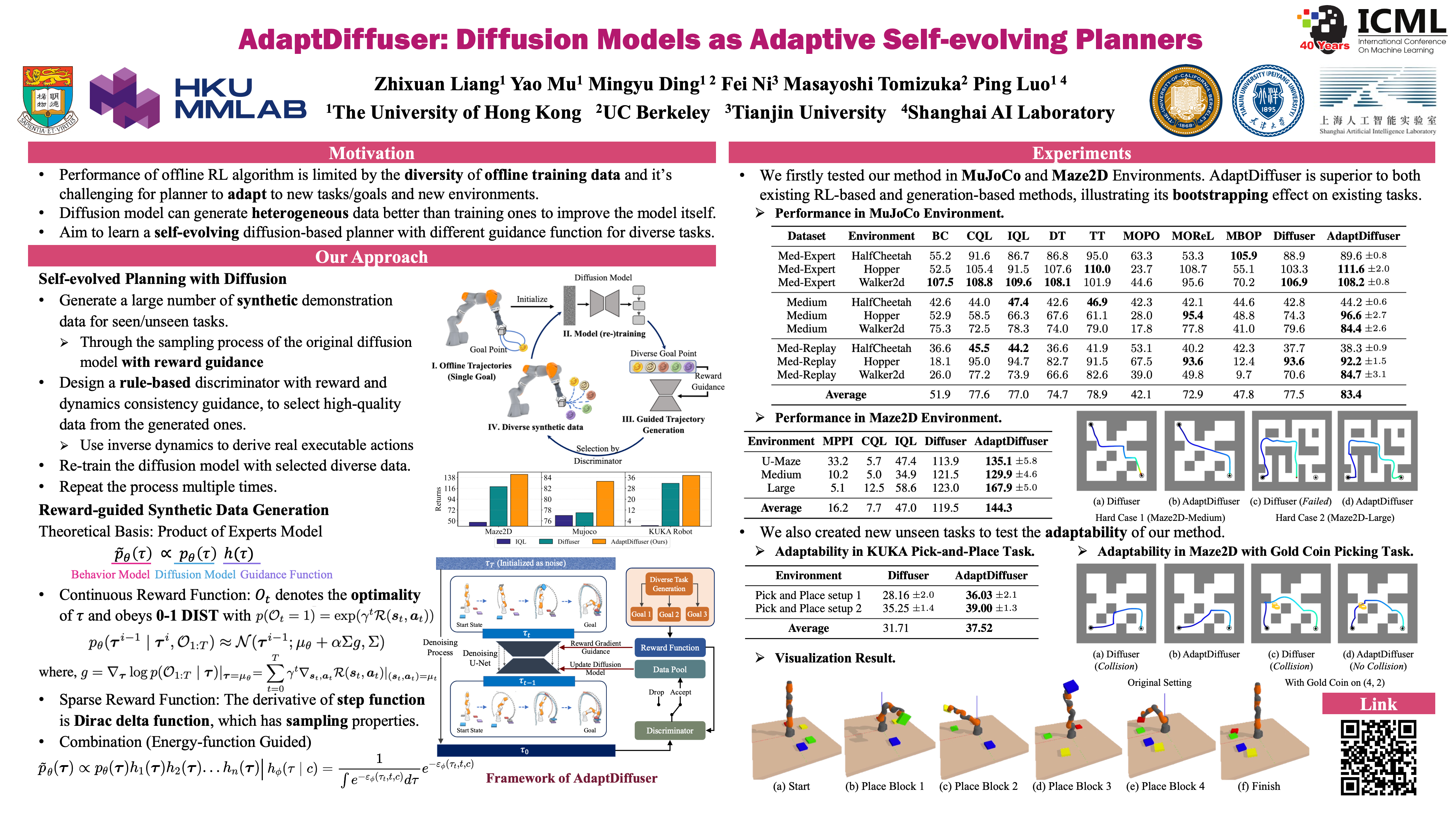
Diffusion models have demonstrated their powerful generative capability in many tasks, with great potential to serve as a paradigm for offline reinforcement learning. However, the quality of the diffusion model is limited by the insufficient diversity of training data, which hinders the performance of planning and the generalizability to new tasks. This paper introduces AdaptDiffuser, an evolutionary planning method with diffusion that can self-evolve to improve the diffusion model hence a better planner, not only for seen tasks but can also adapt to unseen tasks. AdaptDiffuser enables the generation of rich synthetic expert data for goal-conditioned tasks using guidance from reward gradients. It then selects high-quality data via a discriminator to finetune the diffusion model, which improves the generalization ability to unseen tasks. Empirical experiments on two benchmark environments and two carefully designed unseen tasks in KUKA industrial robot arm and Maze2D environments demonstrate the effectiveness of AdaptDiffuser. For example, AdaptDiffuser not only outperforms the previous art Diffuser by 20.8% on Maze2D and 7.5% on MuJoCo locomotion, but also adapts better to new tasks, e.g., KUKA pick-and-place, by 27.9% without requiring additional expert data.
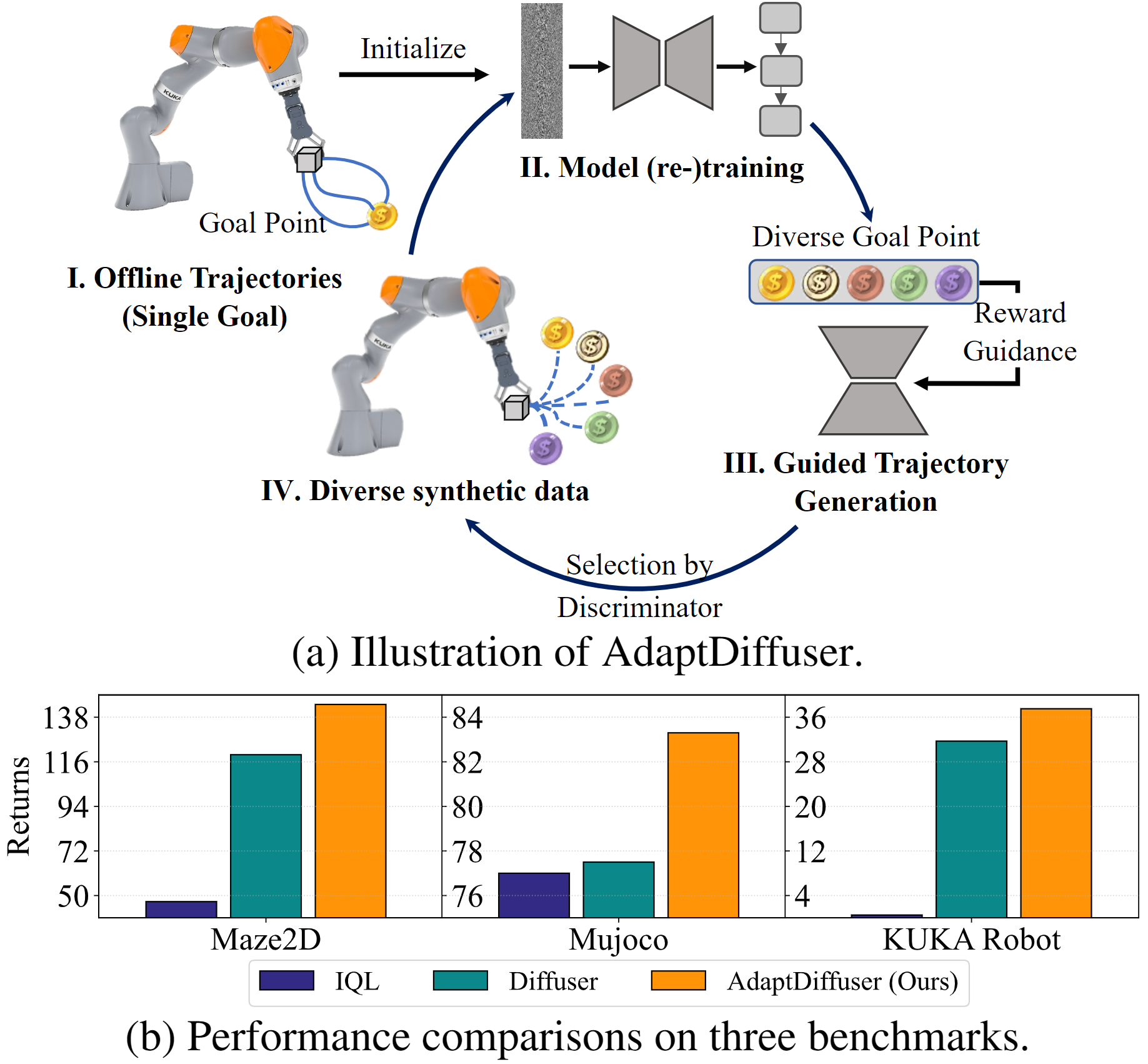
Overall framework and performance comparison of AdaptDiffuser. It enables diffusion models to generate rich synthetic expert data using guidance from reward gradients of either seen or unseen tasks. Then, it iteratively selects high-quality data via a discriminator to fine-tune the model for self-evolving, leading to improved performance on seen tasks and better generalizability to unseen tasks.
Framework of AdaptDiffuser
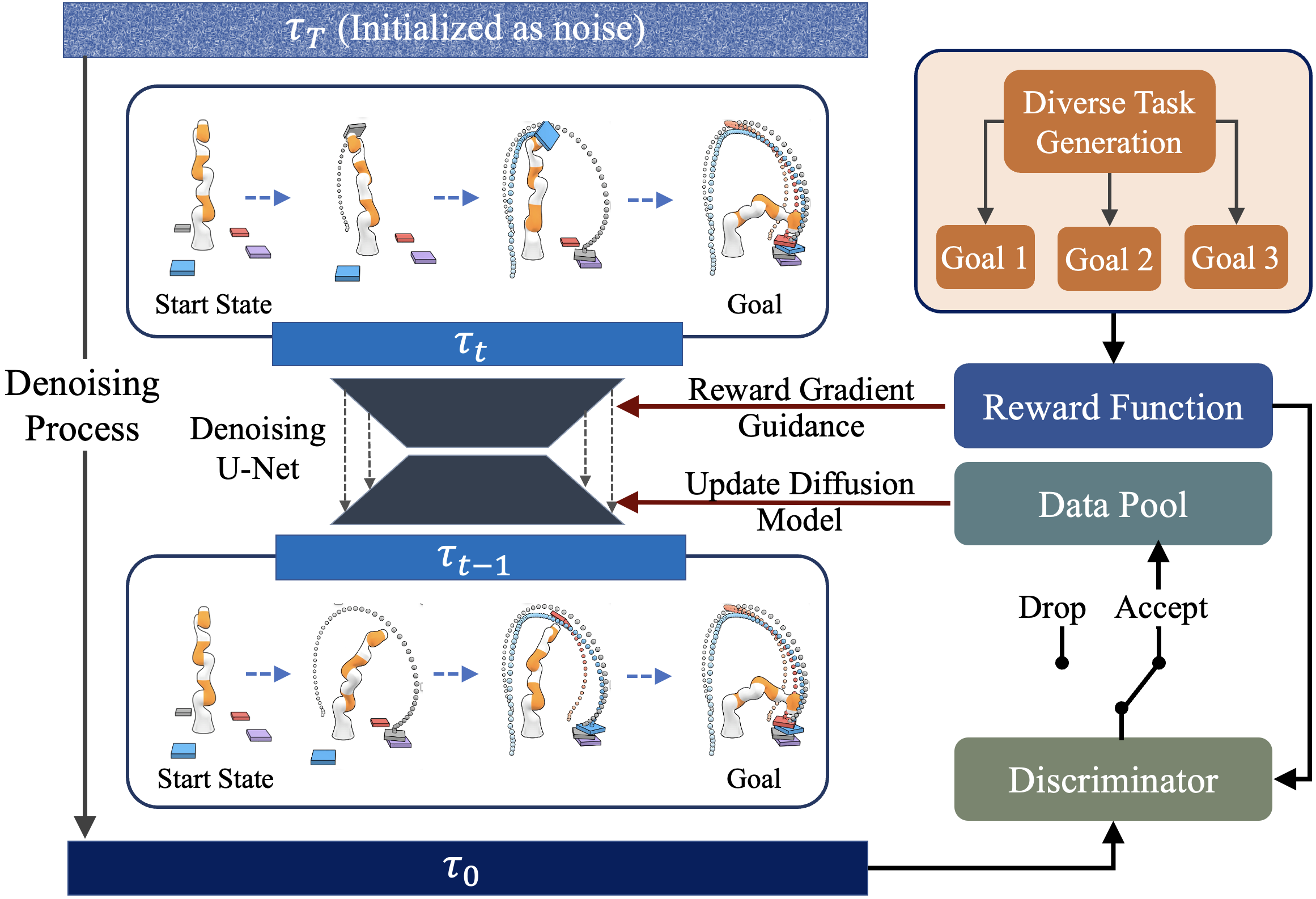
To improve the adaptability of the diffusion model to diverse tasks, rich data with distinct objectives is generated, guided by each task’s reward function. During the diffusion denoising process, we utilize a pre-trained denoising U-Net to progressively generate high-quality trajectories. At each denoising time step, we take the task-specific reward of a trajectory to adjust the gradient of state and action sequence, thereby creating trajectories that align with specific task objectives. Subsequently, the generated synthetic trajectory is evaluated by a discriminator to see if it meets the standards. If yes, it is incorporated into a data pool to fine-tune the diffusion model. The procedure iteratively enhances the generalizability of our model for both seen and unseen settings.

Results
Maze2D Navigation Task
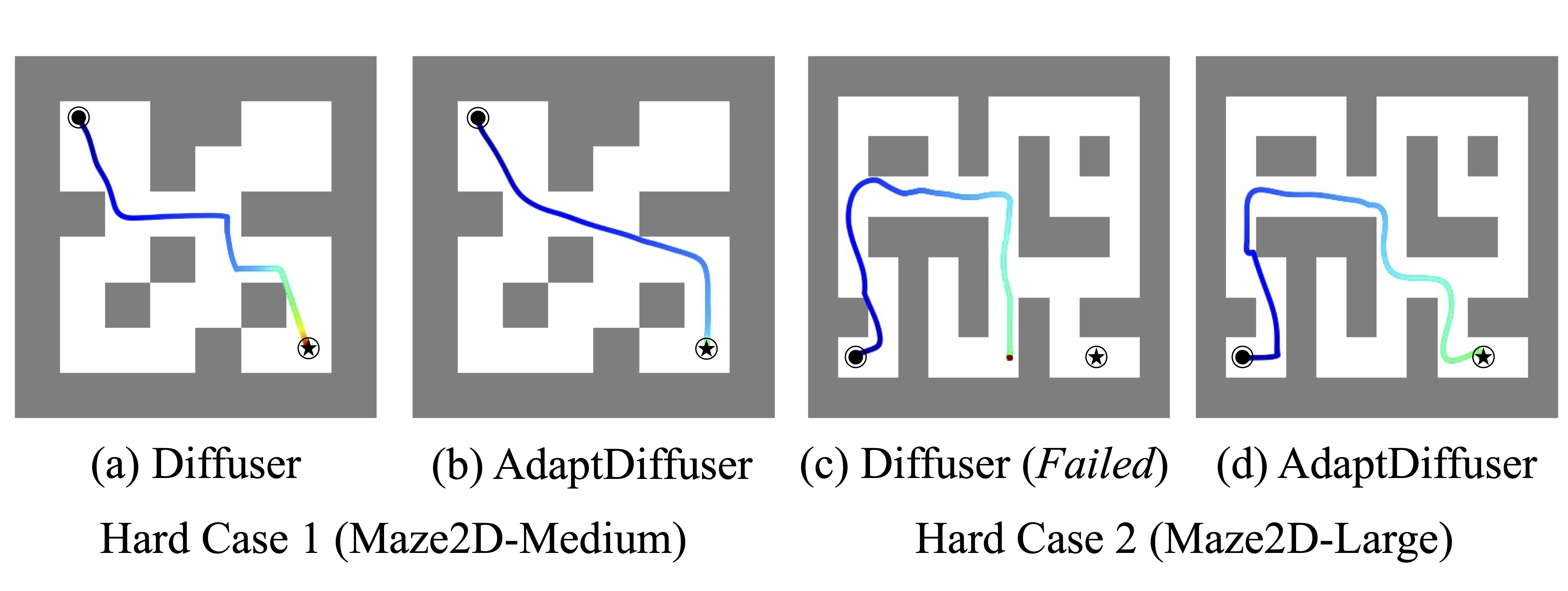
Hard Cases of Maze2D with Long Planning Path. Paths are generated in the Maze2D with a specified start and goal condition.
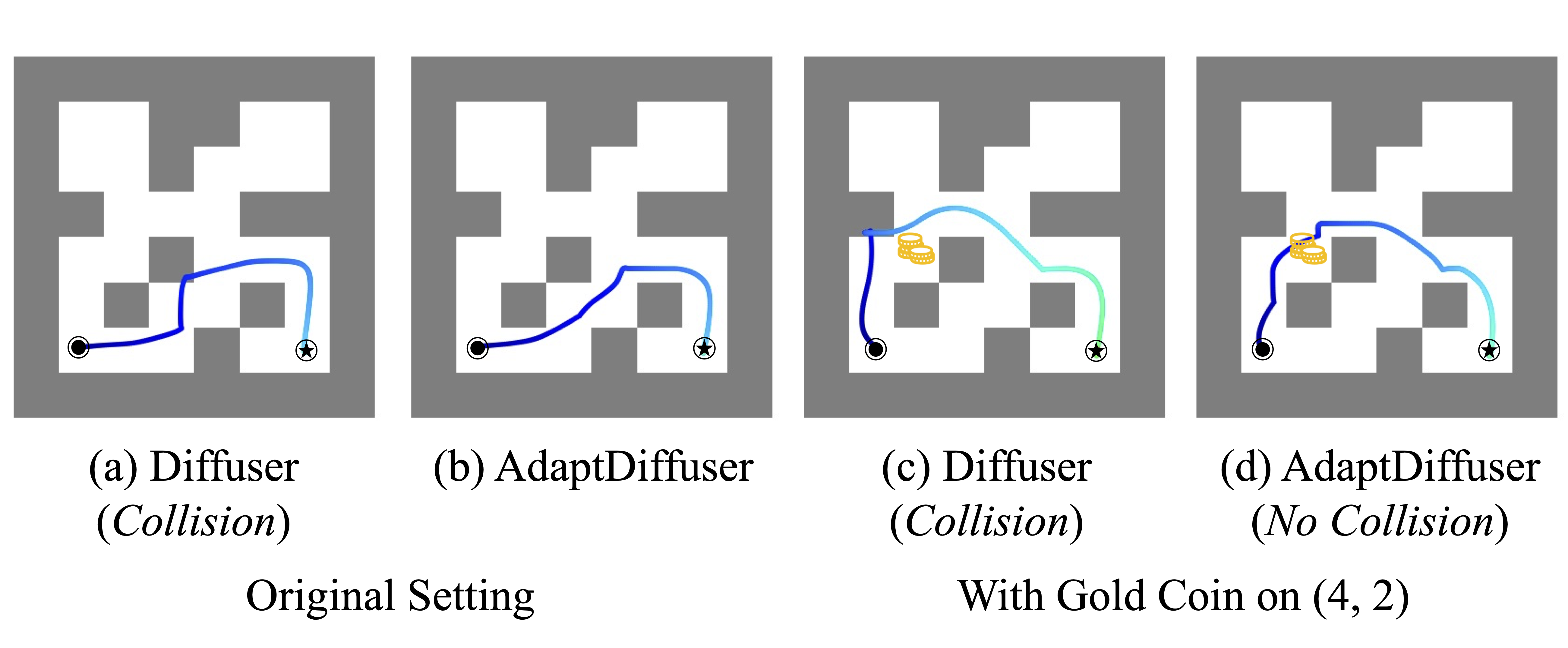
Maze2d Navigation with Gold Coin Picking Task. Subfigures (a) (b) show the optimal path when there are no gold coins in the Maze. (The generated routes walk at the bottom of the Maze.) And subfigures (c) (d) add additional reward in (4, 2) position of the Maze. The planners generate new paths that pass through the gold coin as shown in subfigures (c) (d). (The newly generated routes walk in the middle of the maze.)
MuJoCo Locomotion Task
HalfCheetah Medium
Hopper Medium
Walker2d Medium
Demos of KUKA Pick and Place Task
Bibtex
@inproceedings{liang2023adaptdiffuser,
title={AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners},
author={Liang, Zhixuan and Mu, Yao and Ding, Mingyu and Ni, Fei and Tomizuka, Masayoshi and Luo, Ping},
booktitle={International Conference on Machine Learning},
pages={20725--20745},
year={2023},
organization={PMLR}
}